What’s New in Spark 3
Few new features available in Spark 3.0 which will make it more efficient and faster in execution

Approx 3400 Jiras have been resolved. Majority in SPARK SQL area (46% deployment).
From deployment point of view below are the major focused areas :
1. Performance :
Adaptive Query Execution, Dynamic Partition Pruning, Query Compilation Speed Up, Join Hints
2. Built-in Data Sources:
Parquet/ORC Nested Column Pruning, CSV Filter Pushdown,
Parquet Nested Col Filter Pushdown, New Binary Data Source
3. Richer APIs:
Built-in Function, Pandas UDF Enhancements,
DELETE/UPDATE/MERGE in Catalyst
4. SQL Compatibility:
Overflow Checking, ANSI Store Assignment, Reserved Keywords
5. Extensibility and Ecosystem:
Data Source V2 API + Catalog Support, Hadoop 3 Support,
Hive 3.X Metastore, Hive 2.3 Execution, JDK 11 support
6. Monitoring and Debuggability:
Structured Streaming UI, DDL/DML Enhancements,
Event Log Rollover, Observable Metrics
With all the above changes we are going to experience —
- high performance for batch, interactive, streaming and ML workloads
- Enable new use cases and simplify the Spark application development using richer API and Built-in Functions (approx. 32 new built-in functions)
- Make Monitoring and Debugging Spark application more comprehensive and stable : all new Structured Streaming UI, also make query
execution plan more readable - Enhance the performance and functionalities of the built-in data source
- Improve the plug-in interface and extend the deployment environment
Below are the few major areas which makes Spark 3 way faster in terms of execution.
Adaptive Query Execution
spark query optimizer :
spark 1.X, Rule
spark 2.X, Rule + Cost
spark 3.0, Rule + Cost + Runtime
- Based on the statistics of the finished plan nodes, re-optimize the execution plan of the remaining queries.
- Convert Sort Merge Join to Broadcast Hash Join
- Shrink the number of reducers
- Handle skew join

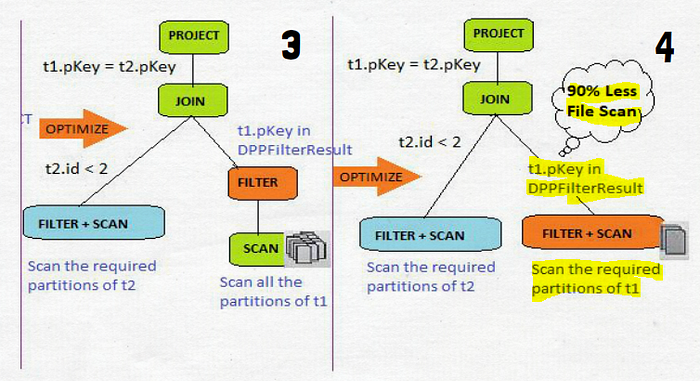
Dynamic Partition Pruning
- Avoid partition scanning based on the query results of the other query fragments
- Significant speed up in terms of execution

Optimizer Hints
Join Hints influence optimizer to choose the following join strategies
Broadcast hash join : one side to be small, no shuffle, no sort, very fast
(SELECT /*+BROADCAST(a)*/ id FROM a JOIN b ON a.key = b.key)
Sort-merge join : robust, can handle any data size, slow when table size is small
(SELECT /*+MERGE(a,b)*/ id FROM a JOIN b ON a.key = b.key)
Shuffle hash join : only shuffle no sort, can handle large table, OOM if data is skewed
(SELECT /*+SHUFFLE_HASH(a,b)*/ id FROM a JOIN b ON a.key = b.key)
Shuffle nested loop join : no join keys required
(SELECT /*+SHUFFLE_REPLICATE_NL(a,b)*/ id FROM a JOIN b)
