APACHE SPARK AND DELTA LAKE, A POWERFUL COMBINATION
Spark is no doubt a powerful processing engine and a distributed cluster computing framework for faster processing. It is getting enriched day by day with additional cool features. Unfortunately there are few areas where spark is struggling. But if we combine Spark with Delta Lake, it can overcomes all those challenges. Few of the drawbacks are —
- Spark is not ACID compliant.
- Issue with Small File processing.
- Lack of Schema enforcement.
1. What is ACID?

1.1. SPARK and ACID:
Let’s check how spark behaves against each A-C-I-D properties.
As per Spark Documentation: “It is important to realize that these save modes (overwrite/append) do not utilize any locking and are not atomic. Additionally, when performing an Overwrite, the data will be deleted before writing out the new data.”
1. ATOMICITY:
So, spark save modes (append/overwrite) are not locking any data and hence are not atomic. Which means there is a high possibility that a failed job may create a fraudulent data. Also, when we use an “overwrite” operation, the data will be deleted before writing the new data, which eventually creates a situation when at a particular time there will be NO Data available.

Scary! Isn’t it? And if our next job fails during its runtime there is a high possibility it will corrupt the entire data or there will be no data at all.
Though the entire situation looks bit scary, but in reality it’s not that bad. Spark dataframe API internally performs job level commit, which helps to achieve some degree of atomicity and these works with “append” mode.
2. CONSISTENCY:
We understood that overwrite mode of Spark writer API will delete the old file first and then will place the new one. So, in between these two states there will be a time when no data will be available. If in between our job fails then we will lose the data. Which means there is no smooth transaction between these two operations. Hence, Spark write mode doesn’t support consistency.
3. ISOLATION:
Isolation means separation. Separation from any other concurrent operation.

Suppose we are writing to a dataset which is not yet committed and there is another concurrent process which reading/writing on the same dataset. As per isolation property, in this situation, one shouldn’t impact other. Basically, any transaction/operation which is currently executing and not yet committed, should be isolated from any other transaction.
Though spark has task level commit and job level commit, but due to lack of atomicity in write operation Spark can’t offer proper isolation.
4. DURABILITY:
It means whatever we have created should not be destroyed. What all the transactions we have committed should be available permanently. There will be some mechanism in place (i.e. log) which will track the details and will help the system to restore the changes during any disaster.

But, during Isolation discussion we understood that spark doesn’t provide proper commit due to lack of atomicity, and without proper commit we can’t expect durability.
If we observer carefully all these ACID properties are interconnected. Due to lack of Atomicity we lose Consistency and Isolation, and due to lack of Isolation we lose Durability.
So far, the summary is :
I) Spark is not ACID compliant.
II) There is a possibility of creating fraudulent data or missing data due to some exception.
III) We need to wait if the same dataset is getting overwritten by some other concurrent process (lack of Isolation)
IV) Because of these limitations Spark is not offering UPDATE or DELETE.
2. Issue with Small File Processing
Spark can’t handle too many small files efficiently. To read data Spark will open and close the file. Now when we will be having huge number of small files, Spark job will spend most of the time to open and close all those files, which will definitely have negative impact on the job execution time.
Again It always refer to the underlying storage system to get the list of the files, which means huge numbers of small file will slow down the listing operation too.
We can compacts small files into larger files to reduce the overall processing time. But as Spark doesn’t support ACID, our main job will be waiting for this compaction job to finish first, which is a drawback.
3. Lack of Schema Enforcement
We know Spark implies Schema on read. Hence when we write any data it will not throw an exception, if there is any. Try to understand this with an example:
Let’s we have an input CSV file with below records

Now, we are trying to read the file → then write it into an Parquet format using ‘overwrite’ mode → read the Parquet file back → and display it
from pyspark.sql import SparkSession
spark = SparkSession.builder.\
config("spark.sql.warehouse.dir", "file:///C:/temp").\
appName("SampleProj").getOrCreate()
# reading the source CSV input file
inputDF = spark.read.format('csv').\
option('header','true').\
option('inferSchema','true').\
load('/Your IP Dir Path/person.csv')
print("--- input CSV file and schema -----")
inputDF.show(truncate=False)
inputDF.printSchema()
# writing to Parquet format
inputDF.write.format('parquet').mode('overwrite').save('/Your IP Dir Path/OP/')
# reading the same Parquet file
readDF = spark.read.format('parquet').load('/Your IP Dir Path/OP/')
print("--- Parquet file reading done -----")
# display the data
readDF.show(truncate=False)
readDF.printSchema()
print("--- I'm done -----")So, it’s a simple program only to read, write and display the data. The expected output is as below —

All good so far. We are able to read , write and display back the same data set.
Let’s we have another input CSV file with same column but the ‘Weight’ column has decimal values instead of integer (as shown below).

We are using the same above program to read the CSV, write into Parquet, read it back and display. But instead of using overwrite we will use append to write the Parquet file.
# writing to Parquet format
inputDF.write.format('parquet').mode('append').save('/Your IP Dir Path/OP/')In this case our program will read the CSV, write into Parquet format and read the Parquet file back without any exception. The moment we want to show/display the dataframe our program will throw an error “java.lang.UnsupportedOperationException: Unimplemented type: IntegerType”.

It’s happening because Spark never validates schema during write operation. The schema of ‘Weight’ column changes from Integer to Double and Spark writes the data without any issue. The moment we read the appended data and call an Action it throws error due to incompatibility of the schema.
How to Overcome?
The above problems can be managed if we plugin Delta Lake as an additional service with Spark. Spark usages underlying distributed system like HDFS, S3 etc to store data.

Now, instead of doing this if we make Spark talking to Delta Lake and Delta Lake will communicate further with underlying distributed storage, then easily we can make Spark to inherit Delta lake ACID attributes and other useful properties.

What is Delta Lake?
Before that let’s take a quick look what is Data Lake? We can consider Data Lake as a centralized data repository with massive scale and open formats which can stores both Structured and Unstructured raw data. But there are few areas where it is lacking, like — inconsistent data, lack of schema and issue with performance.
Here comes Delta Lake! Delta Lake is an open source storage layer that brings reliability to Data Lakes. Delta Lake provides ACID transactions, Schema enforcement, scalable metadata handling, and unifies streaming and batch data processing. Most importantly, Delta Lake runs on top of our existing Data Lake (Parquet file storage) and is fully compatible with Apache Spark APIs.
Few important features Delta Lake offers to Spark:
1. ACID transactions.
2. Schema enforcement / schema validation.
3. Enables Updates, Deletes and Merge.
4. Time Travel/Versioning (look back to historic data)
Spark With Delta Lake — Schema Enforcement Example :
Let’s consider the same 2 data files (with different datatypes — ‘Weight column’, as used in previous example) to check how spark behaves when it’s overwriting data using Delta Lake.

Let’s read the data:

Writing the data without Delta Lake:

Writing the data with Delta Lake:

So far no issue and we are able to write data with and without Delta Lake using ‘overwrite’ mode.
Let’s read the 2nd file having different column type (Weight is double here):

As tested already, no issue to overwrite schema mismatched data without using Delta Lake:

But, if we use Delta Lake to write the same data, it will throw an error: “Failed to merge incompatible data types IntegerType and DoubleType”

So, we can see Delta Lake validates the schema before writing into underlying system, which means Delta Lake uses schema validation on write,. If the schema is not compatible then Delta Lake will cancel the transaction. This will help to track the issue at the beginning rather mixing up with good data and then try to find out the root cause.
Mainly it validates below 3 points during writing any data:
1. The column data types should be same as the target table.
2. Number of columns should be same as target table.
3. Column names should be same as target table.
Note: by default Delta Lake will not allow to write data having different number of columns (point #2). But we can force to append these files by using .option(“mergeSchema”, “true”) during writing our data based on the need.
Spark With Delta Lake — Enables Update and Delete Example :
Spark never allows us to run Update or Delete statements. But, if we use Delta Lake we can easily perform these kind of operations.
Let’s consider the below file as our input data:

Reading the data:

Save as Delta Lake Table:


Let’s UPDATE few records:




Let’s DELETE records from the same table:


So, we can see by using Delta Lake it’s very easy to utilize the DELETE, UPDATE commands
How does Delete, Update and Merge works?
The below structure represents how does Delta Lake maintain the version details for each DML transaction. It maintains a Transaction Log which captures all the operations performed on the file. Inside our folder structure there is a _delta_log folder which contains the JSON logs. These JSON logs will be having all this transaction details. For each DML operation (performs over the period of time) there will be a separate JSON created, which represents the version of the table. So, the whole Delta Lake table is versioned and we can easily query back.
Also, there is a Parquet file, which holds the actual processed data. (In the below figure we consider our data is partitioned by date)
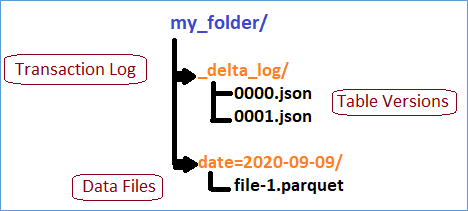
So, let’s understand how does UPDATE , DELETE and MERGE works.
UPDATE under the hood:
Delta Lake stores the data as a Parquet file, and we know Parquet files are not designed to be replaced or update. Which means Delta Lake can’t run DML straight away on its underlying files. It performs 2 level of scanning to Update any file.
Let’s consider there are 5 parquet files inside our data file directory. These 5 files contain our processed data and assume these files represent version 1.
SQL Statement: UPDATE table SET col1 = value WHERE <predicates>
Scan 1: Based on the defined predicates it will find and select the underlying files which contain the matching records. In the below image, the Grey boxes (file1, file3 and file5) represent files which has no matches at all. Other 2 files (file2 and file4) have partial matches, few rows of parquet file matched the predicates. The Blue sections represent rows with matched records where Yellow again non matching records but they belong to the files with matches.

Scan 2: Once the files are getting identified (via Scan 1), it will rewrite those files. Because, underlying parquet can’t be deleted or updated.

The rows matched the predicate (blue parts) will be updated in the new files where unmatched records (yellow parts) will be simply copied into those new files.
All the Tombstone files (where no matched found) will not be physically deleted, rather, in the transaction log (JSON files — as defined in fig-1) these files will be marked as “Removed”. This will help to maintain the version history and will be used during time travel.
Python approach:
from delta.tables import *
from pyspark.sql.function import *dt = DeltaTable.forPath(spark, "/deltaPath")
dt.update("Name = ‘Tim’", {"Height":157})
DELETE under the hood:
As we have seen UPDATE never physically removes old files, same way DELETE does not remove data on disk until we execute VACUUM command. Same as Update, Delete rewrites new files where predicates are observed and keeps the old files for time travel queries. So, accidentally if we delete some data we can query previous versions to get the data back. Happy !!
If we feel old records are not so important and we can store only for a certain time range, we can use VACUUM to delete the unwanted data permanently.
VACUUM table [RETAIN t HOURS]
The above statement says delete all old files earlier than “t” hours. The default vacuum retention period is 7 days. Never use vacuum with zero (0) retention, unless we are very sure. This will remove all versions except the latest one and will create inconsistency if some other process is writing on the same file.
Python approach:
from delta.tables import *
from pyspark.sql.function import *dt = DeltaTable.forPath(spark, "/deltaPath")
dt.delete("predicate")
MERGE under the hood:
Merge is a very powerful operation. It will help us to update, delete or insert records based on conditions.
First understand why Merge is so important. Assume we want to execute Insert/Update on underlying records. Let’s compare the steps involved to run the same operation on Parquet table (Data Lake) with a legacy data pipeline and Delta Lake.

It’s quite obvious, there are multiple steps involved to perform the activity with traditional Parquet data store, where MERGE will take care of all after identifying the rows in Delta Lake for us.
So, how does MERGE work? The behind story is more or less same, likewise Update and Delete, Merge also finds out the matched records, create a new file and then apply the changes, but it uses JOIN operations to do so.
Scan 1: It runs INNER JOIN between source and target tables to identify the matched files (fig-2).
Scan 2: Then it performs OUTER JOIN between matched files in target and source. And then apply Update/Delete/Insert operations on those records.
Python approach:
from delta.tables import *
from pyspark.sql.function import *dt = DeltaTable.forPath(spark, deltaPath)dt.alias(“t”)
.merge(sourceDF.alias(“s”), “t.id = s.id”)
.whenMatchedUpdateAll()
.whenNotMatchedInsertAll()
.execute()
SQL approach:
MERGE into target t
USING source s
ON t.id = s.id
WHEN MATCHED [optional [and <additional conditions>]] THEN UPDATE SET *
WHEN MATCHED THEN DELETE
WHEN NOT MATCHED [optional [and <additional conditions>]] THEN INSERT *Spark With Delta Lake — Time Travel Example :
So far we have discussed about - Transaction logs, that contains all the action details performed on that specific version file. Then, how does Delta keep all the old files and maintain the version history during DML operations. Also, it never physically deletes files (except vacuum), rather marked them as removed.
All these behaviors help us to go back and pull the older records based on our need.
Display(deltaTable.history())
Basically, we are not loosing any old transactions inside Delta. The version history will display all the details and we can load historic data by using the version number, timestamp etc.
We can use dataframe API to pull the records based on version or timestamp like:
# version specific
DF = spark.read.format("delta").option("versionAsOf", 3).load("/deltaFilePath")# timestamp specific
DF = spark.read.format("delta").option("timestampAsOf", "2020-09-18T13:28:55").load("/deltaFilePath")
Note: don’t hold the old parquet files (actual data file) unnecessary. More old data files means execution process will take longer time to scan through all of them. It’s always a good practice to VACUUM data files for certain intervals (ex. 7 days). But all the transaction logs (JSON files) will be available under _delta_log directory.
This is it! A quick overview how to overcome the traditional drawbacks of Spark, what we can achieve combining Spark with Delta Lake and how efficiently data can be managed.
HAPPY LEARNING !!